52. Optimal Growth I: The Stochastic Optimal Growth Model#
Contents
52.1. Overview#
In this lecture, we’re going to study a simple optimal growth model with one agent.
The model is a version of the standard one sector infinite horizon growth model studied in
[Stokey et al., 1989], chapter 2
[Ljungqvist and Sargent, 2018], section 3.1
EDTC, chapter 1
[Sundaram, 1996], chapter 12
It is an extension of the simple cake eating problem we looked at earlier.
The extension involves
nonlinear returns to saving, through a production function, and
stochastic returns, due to shocks to production.
Despite these additions, the model is still relatively simple.
We regard it as a stepping stone to more sophisticated models.
We solve the model using dynamic programming and a range of numerical techniques.
In this first lecture on optimal growth, the solution method will be value function iteration (VFI).
While the code in this first lecture runs slowly, we will use a variety of techniques to drastically improve execution time over the next few lectures.
Let’s start with some imports:
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (11, 5) #set default figure size
import numpy as np
from scipy.interpolate import interp1d
from scipy.optimize import minimize_scalar
52.2. The Model#
Consider an agent who owns an amount
This output can either be consumed or invested.
When the good is invested, it is transformed one-for-one into capital.
The resulting capital stock, denoted here by
Production is stochastic, in that it also depends on a shock
Next period output is
where
The resource constraint is
and all variables are required to be nonnegative.
52.2.1. Assumptions and Comments#
In what follows,
The sequence
The common distribution of each
The production function
Depreciation of capital is not made explicit but can be incorporated into the production function.
While many other treatments of the stochastic growth model use
This will allow us to treat a stochastic model while maintaining only one state variable.
We consider alternative states and timing specifications in some of our other lectures.
52.2.2. Optimization#
Taking
subject to
where
In (52.3) we are assuming that the resource constraint (52.1) holds with equality — which is reasonable because
In summary, the agent’s aim is to select a path
nonnegative,
feasible in the sense of (52.1),
optimal, in the sense that it maximizes (52.2) relative to all other feasible consumption sequences, and
adapted, in the sense that the action
In the present context
52.2.3. The Policy Function Approach#
One way to think about solving this problem is to look for the best policy function.
A policy function is a map from past and present observables into current action.
We’ll be particularly interested in Markov policies, which are maps from the current state
For dynamic programming problems such as this one (in fact for any Markov decision process), the optimal policy is always a Markov policy.
In other words, the current state
This is quite intuitive, but if you wish you can find proofs in texts such as [Stokey et al., 1989] (section 4.1).
Hereafter we focus on finding the best Markov policy.
In our context, a Markov policy is a function
In what follows, we will call
In other words, a feasible consumption policy is a Markov policy that respects the resource constraint.
The set of all feasible consumption policies will be denoted by
Each
This is the time path for output when we choose and stick with the policy
We insert this process into the objective function to get
This is the total expected present value of following policy
The aim is to select a policy that makes this number as large as possible.
The next section covers these ideas more formally.
52.2.4. Optimality#
The
when
In other words, it is the lifetime value of following policy
The value function is then defined as
The value function gives the maximal value that can be obtained from state
A policy
52.2.5. The Bellman Equation#
With our assumptions on utility and production functions, the value function as defined in (52.8) also satisfies a Bellman equation.
For this problem, the Bellman equation takes the form
This is a functional equation in
The term
the state is
consumption is set to
As shown in EDTC, theorem 10.1.11 and a range of other texts
The value function
satisfies the Bellman equation
In other words, (52.9) holds when
The intuition is that maximal value from a given state can be obtained by optimally trading off
current reward from a given action, vs
expected discounted future value of the state resulting from that action
The Bellman equation is important because it gives us more information about the value function.
It also suggests a way of computing the value function, which we discuss below.
52.2.6. Greedy Policies#
The primary importance of the value function is that we can use it to compute optimal policies.
The details are as follows.
Given a continuous function
for every
In other words,
In our setting, we have the following key result
A feasible consumption policy is optimal if and only if it is
The intuition is similar to the intuition for the Bellman equation, which was provided after (52.9).
See, for example, theorem 10.1.11 of EDTC.
Hence, once we have a good approximation to
The advantage is that we are now solving a much lower dimensional optimization problem.
52.2.7. The Bellman Operator#
How, then, should we compute the value function?
One way is to use the so-called Bellman operator.
(An operator is a map that sends functions into functions.)
The Bellman operator is denoted by
In other words,
By construction, the set of solutions to the Bellman equation
(52.9) exactly coincides with the set of fixed points of
For example, if
which says precisely that
It follows that
52.2.8. Review of Theoretical Results#
One can also show that
See EDTC, lemma 10.1.18.
Hence, it has exactly one fixed point in this set, which we know is equal to the value function.
It follows that
The value function
Starting from any bounded and continuous
This iterative method is called value function iteration.
We also know that a feasible policy is optimal if and only if it is
It’s not too hard to show that a
Hence, at least one optimal policy exists.
Our problem now is how to compute it.
52.2.9. Unbounded Utility#
The results stated above assume that the utility function is bounded.
In practice economists often work with unbounded utility functions — and so will we.
In the unbounded setting, various optimality theories exist.
Unfortunately, they tend to be case-specific, as opposed to valid for a large range of applications.
Nevertheless, their main conclusions are usually in line with those stated for the bounded case just above (as long as we drop the word “bounded”).
Consult, for example, section 12.2 of EDTC, [Kamihigashi, 2012] or [Martins-da-Rocha and Vailakis, 2010].
52.3. Computation#
Let’s now look at computing the value function and the optimal policy.
Our implementation in this lecture will focus on clarity and flexibility.
Both of these things are helpful, but they do cost us some speed — as you will see when you run the code.
Later we will sacrifice some of this clarity and flexibility in order to accelerate our code with just-in-time (JIT) compilation.
The algorithm we will use is fitted value function iteration, which was described in earlier lectures the McCall model and cake eating.
The algorithm will be
Begin with an array of values
Build a function
Obtain and record the value
Unless some stopping condition is satisfied, set
52.3.1. Scalar Maximization#
To maximize the right hand side of the Bellman equation (52.9), we are going to use
the minimize_scalar routine from SciPy.
Since we are maximizing rather than minimizing, we will use the fact that the
maximizer of
To this end, and to keep the interface tidy, we will wrap minimize_scalar
in an outer function as follows:
def maximize(g, a, b, args):
"""
Maximize the function g over the interval [a, b].
We use the fact that the maximizer of g on any interval is
also the minimizer of -g. The tuple args collects any extra
arguments to g.
Returns the maximal value and the maximizer.
"""
objective = lambda x: -g(x, *args)
result = minimize_scalar(objective, bounds=(a, b), method='bounded')
maximizer, maximum = result.x, -result.fun
return maximizer, maximum
52.3.2. Optimal Growth Model#
We will assume for now that
We will store this and other primitives of the optimal growth model in a class.
The class, defined below, combines both parameters and a method that realizes the right hand side of the Bellman equation (52.9).
class OptimalGrowthModel:
def __init__(self,
u, # utility function
f, # production function
β=0.96, # discount factor
μ=0, # shock location parameter
s=0.1, # shock scale parameter
grid_max=4,
grid_size=120,
shock_size=250,
seed=1234):
self.u, self.f, self.β, self.μ, self.s = u, f, β, μ, s
# Set up grid
self.grid = np.linspace(1e-4, grid_max, grid_size)
# Store shocks (with a seed, so results are reproducible)
np.random.seed(seed)
self.shocks = np.exp(μ + s * np.random.randn(shock_size))
def state_action_value(self, c, y, v_array):
"""
Right hand side of the Bellman equation.
"""
u, f, β, shocks = self.u, self.f, self.β, self.shocks
v = interp1d(self.grid, v_array)
return u(c) + β * np.mean(v(f(y - c) * shocks))
In the second last line we are using linear interpolation.
In the last line, the expectation in (52.11) is computed via Monte Carlo, using the approximation
where
Monte Carlo is not always the most efficient way to compute integrals numerically but it does have some theoretical advantages in the present setting.
(For example, it preserves the contraction mapping property of the Bellman operator — see, e.g., [Pál and Stachurski, 2013].)
52.3.3. The Bellman Operator#
The next function implements the Bellman operator.
(We could have added it as a method to the OptimalGrowthModel class, but we
prefer small classes rather than monolithic ones for this kind of
numerical work.)
def T(v, og):
"""
The Bellman operator. Updates the guess of the value function
and also computes a v-greedy policy.
* og is an instance of OptimalGrowthModel
* v is an array representing a guess of the value function
"""
v_new = np.empty_like(v)
v_greedy = np.empty_like(v)
for i in range(len(grid)):
y = grid[i]
# Maximize RHS of Bellman equation at state y
c_star, v_max = maximize(og.state_action_value, 1e-10, y, (y, v))
v_new[i] = v_max
v_greedy[i] = c_star
return v_greedy, v_new
52.3.4. An Example#
Let’s suppose now that
For this particular problem, an exact analytical solution is available (see [Ljungqvist and Sargent, 2018], section 3.1.2), with
and optimal consumption policy
It is valuable to have these closed-form solutions because it lets us check whether our code works for this particular case.
In Python, the functions above can be expressed as:
def v_star(y, α, β, μ):
"""
True value function
"""
c1 = np.log(1 - α * β) / (1 - β)
c2 = (μ + α * np.log(α * β)) / (1 - α)
c3 = 1 / (1 - β)
c4 = 1 / (1 - α * β)
return c1 + c2 * (c3 - c4) + c4 * np.log(y)
def σ_star(y, α, β):
"""
True optimal policy
"""
return (1 - α * β) * y
Next let’s create an instance of the model with the above primitives and assign it to the variable og.
α = 0.4
def fcd(k):
return k**α
og = OptimalGrowthModel(u=np.log, f=fcd)
Now let’s see what happens when we apply our Bellman operator to the exact
solution
In theory, since
In practice, we expect some small numerical error.
grid = og.grid
v_init = v_star(grid, α, og.β, og.μ) # Start at the solution
v_greedy, v = T(v_init, og) # Apply T once
fig, ax = plt.subplots()
ax.set_ylim(-35, -24)
ax.plot(grid, v, lw=2, alpha=0.6, label='$Tv^*$')
ax.plot(grid, v_init, lw=2, alpha=0.6, label='$v^*$')
ax.legend()
plt.show()
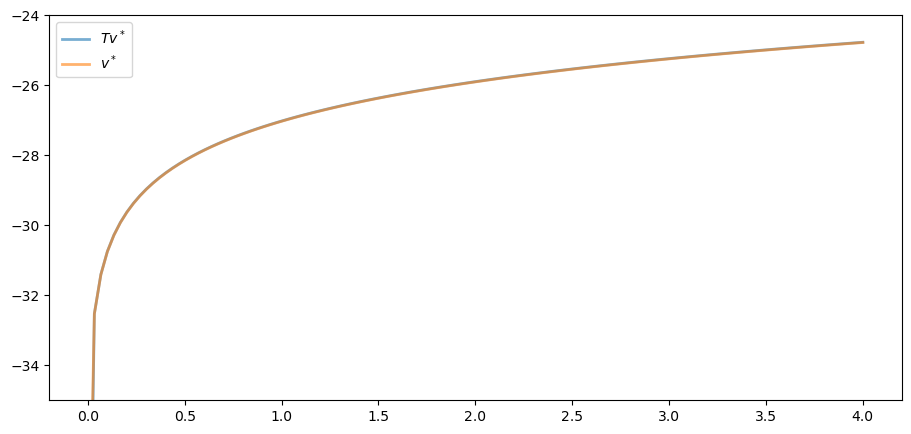
The two functions are essentially indistinguishable, so we are off to a good start.
Now let’s have a look at iterating with the Bellman operator, starting from an arbitrary initial condition.
The initial condition we’ll start with is, somewhat arbitrarily,
v = 5 * np.log(grid) # An initial condition
n = 35
fig, ax = plt.subplots()
ax.plot(grid, v, color=plt.cm.jet(0),
lw=2, alpha=0.6, label='Initial condition')
for i in range(n):
v_greedy, v = T(v, og) # Apply the Bellman operator
ax.plot(grid, v, color=plt.cm.jet(i / n), lw=2, alpha=0.6)
ax.plot(grid, v_star(grid, α, og.β, og.μ), 'k-', lw=2,
alpha=0.8, label='True value function')
ax.legend()
ax.set(ylim=(-40, 10), xlim=(np.min(grid), np.max(grid)))
plt.show()
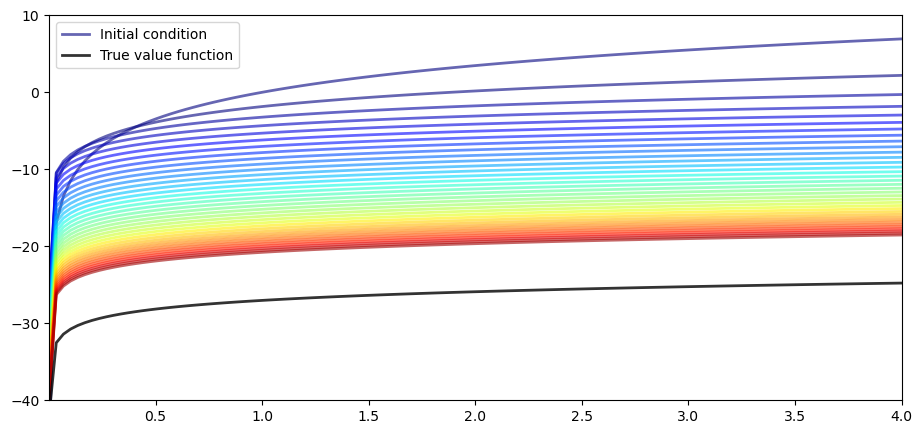
The figure shows
the first 36 functions generated by the fitted value function iteration algorithm, with hotter colors given to higher iterates
the true value function
The sequence of iterates converges towards
We are clearly getting closer.
52.3.5. Iterating to Convergence#
We can write a function that iterates until the difference is below a particular tolerance level.
def solve_model(og,
tol=1e-4,
max_iter=1000,
verbose=True,
print_skip=25):
"""
Solve model by iterating with the Bellman operator.
"""
# Set up loop
v = og.u(og.grid) # Initial condition
i = 0
error = tol + 1
while i < max_iter and error > tol:
v_greedy, v_new = T(v, og)
error = np.max(np.abs(v - v_new))
i += 1
if verbose and i % print_skip == 0:
print(f"Error at iteration {i} is {error}.")
v = v_new
if error > tol:
print("Failed to converge!")
elif verbose:
print(f"\nConverged in {i} iterations.")
return v_greedy, v_new
Let’s use this function to compute an approximate solution at the defaults.
v_greedy, v_solution = solve_model(og)
Error at iteration 25 is 0.40975776844489786.
Error at iteration 50 is 0.1476753540823772.
Error at iteration 75 is 0.05322171277214238.
Error at iteration 100 is 0.01918093054865011.
Error at iteration 125 is 0.006912744396025516.
Error at iteration 150 is 0.0024913303848101975.
Error at iteration 175 is 0.0008978672913073638.
Error at iteration 200 is 0.0003235884239707332.
Error at iteration 225 is 0.00011662020562397402.
Converged in 229 iterations.
Now we check our result by plotting it against the true value:
fig, ax = plt.subplots()
ax.plot(grid, v_solution, lw=2, alpha=0.6,
label='Approximate value function')
ax.plot(grid, v_star(grid, α, og.β, og.μ), lw=2,
alpha=0.6, label='True value function')
ax.legend()
ax.set_ylim(-35, -24)
plt.show()
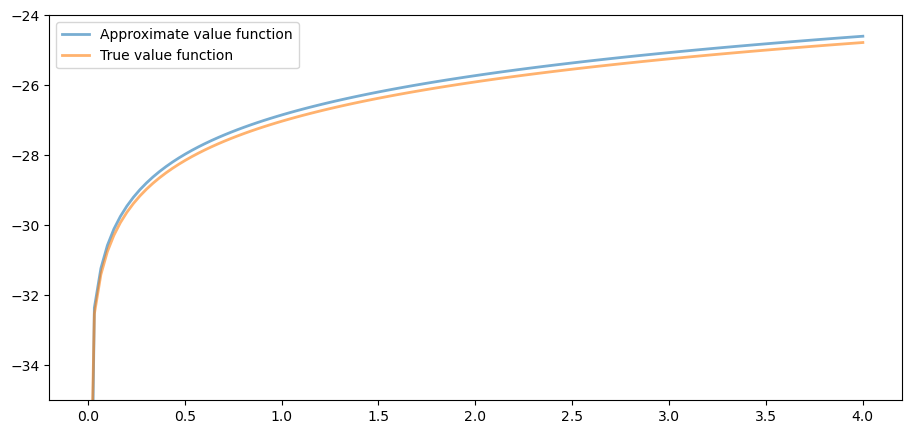
The figure shows that we are pretty much on the money.
52.3.6. The Policy Function#
The policy v_greedy computed above corresponds to an approximate optimal policy.
The next figure compares it to the exact solution, which, as mentioned
above, is
fig, ax = plt.subplots()
ax.plot(grid, v_greedy, lw=2,
alpha=0.6, label='approximate policy function')
ax.plot(grid, σ_star(grid, α, og.β), '--',
lw=2, alpha=0.6, label='true policy function')
ax.legend()
plt.show()
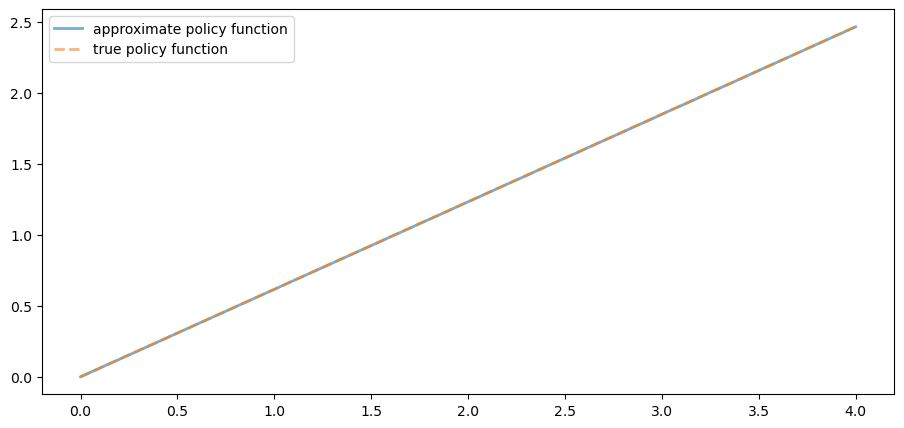
The figure shows that we’ve done a good job in this instance of approximating the true policy.
52.4. Exercises#
Exercise 52.1
A common choice for utility function in this kind of work is the CRRA specification
Maintaining the other defaults, including the Cobb-Douglas production function, solve the optimal growth model with this utility specification.
Setting
Time how long this function takes to run, so you can compare it to faster code developed in the next lecture.
Solution to Exercise 52.1
Here we set up the model.
γ = 1.5 # Preference parameter
def u_crra(c):
return (c**(1 - γ) - 1) / (1 - γ)
og = OptimalGrowthModel(u=u_crra, f=fcd)
Now let’s run it, with a timer.
%%time
v_greedy, v_solution = solve_model(og)
Error at iteration 25 is 0.5528151810417512.
Error at iteration 50 is 0.19923228425591333.
Error at iteration 75 is 0.07180266113800826.
Error at iteration 100 is 0.025877443335843964.
Error at iteration 125 is 0.009326145618928194.
Error at iteration 150 is 0.003361112262005861.
Error at iteration 175 is 0.001211333824251426.
Error at iteration 200 is 0.0004365607333056687.
Error at iteration 225 is 0.00015733505506432266.
Converged in 237 iterations.
CPU times: user 28.6 s, sys: 3.01 ms, total: 28.6 s
Wall time: 28.6 s
Let’s plot the policy function just to see what it looks like:
fig, ax = plt.subplots()
ax.plot(grid, v_greedy, lw=2,
alpha=0.6, label='Approximate optimal policy')
ax.legend()
plt.show()
Exercise 52.2
Time how long it takes to iterate with the Bellman operator
20 times, starting from initial condition
Use the model specification in the previous exercise.
(As before, we will compare this number with that for the faster code developed in the next lecture.)
Solution to Exercise 52.2
Let’s set up:
og = OptimalGrowthModel(u=u_crra, f=fcd)
v = og.u(og.grid)
Here’s the timing:
%%time
for i in range(20):
v_greedy, v_new = T(v, og)
v = v_new
CPU times: user 2.42 s, sys: 1 μs, total: 2.42 s
Wall time: 2.42 s